
By Mischa Obrecht
We have recently witnessed the advent of artificial intelligence, machine and deep learning technologies, which have led to a tremendous amount of interest from almost every other area of science, technology and business. The area of cyber-security is no exception. It is however interesting, that most security vendors and consultants keep a cloak of silence around specific AI-enabled cyber-security use cases and thus specific examples of how AI and machine learning are used in the context of cyber-security are rather scarce.
This blog post is about introducing such a use case where we successully attempt to use deep neural networks to identify suspicious domains in the full *.ch domain-space.
Introduction
Dreamlab has been involved in the Horizon 2020 project «Sharing and Automation for Privacy Preserving Attack Neutralization» (SAPPAN, [1]) as a consortium partner since its inception in 2019. SAPPAN is investigating ways to improve detection and response of cyber-security incidents by sharing of information and automation of response and remediation actions.
A variety of research topics regarding detection of cyber-security incidents has been performed in the context of SAPPAN. One of these topics concerns itself with the detection of algorithmically generated domains (AGDs) by using deep learning classifiers (cf. for example [2]). After having been introduced to this kind of research, our research team at Dreamlab decided to try to apply this technology to a topic close to Dreamlab’s heart: The Swiss Cyber-Space in its entirety.
Our goal
As switch.ch recently published the .ch-zonefile [3], we have access to a snapshot of all registered *.ch domains, including all the domains that may never have been configured to resolve to an IP, are not linked to by any websites or webservices and are thus not discovered by web-crawlers like Google or services like securitytrails.com. This means that we are perfectly positioned  to take a close look at the complete .ch-domain space.
Our goal is to find a self contained way for automatically identifying suspicious domains in the .ch-zone almost exclusively based on information contained in the domain-name itself. Such a method complements existing methods like blacklisting and the utilization of reputation services. One big advantage of the method we are about to present is that it can be employed at scale in a network monitoring solution like Dreamlab’s CySOC [4], where every second thousands of domains are recorded and analysed. Another big advantage is that our method also works for previously unknown domains, since it does not rely on previously seen malicious activity or other indicators like domain age, geolocation or AS-membership.
Outlook
The reminder of this article is structured as follows:
- An introduction to domain generation algorithms and their significance
- An introduction of a classification method based on deep neural networks, which is able to classify algorithmically generated domains with high accuracy as well as some tweaks that were necessary to narrow the results down to a manageable amount for the *.ch-zone.
- Results of applying our approach to the .ch-zone
Domain Generation Algorithms and their significance
Modern remote controlled malware (so called remote access toolkits, that are widely used by advanced persistent threats, APTs) communicates with its handler. This is called command and control (C2). In most cases the malware will contact a public rendez-vous server or public proxy (e.g. a virtual private server on AWS) to obtain instructions from its handler in more or less regular intervals. This is called beaconing. More often than not these public servers and proxies are third-party systems that the malicious actor is abusing without the owner’s knowledge, to further protect the attacker’s own infrastructure and increase operational security. Figure 1 shows an example of such a setup.
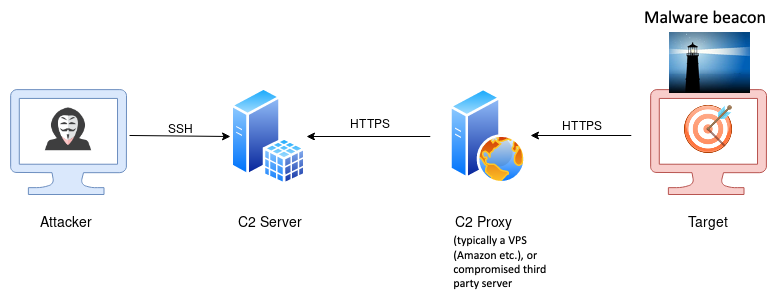
Figure 1: A typical setup of modern remote controlled malware (based on illustration from https://poshc2.readthedocs.io/en/latest/install_and_setup/architecture.html)
Depending on the level of sophistication shown by the malware and its handlers this kind of communication can be easy or very hard to detect and disrupt. Generally there are two ways to to this:
Detecting malicious communication based on content
This is for instance possible if the malware is using an unencrypted communication protocol, like HTTP over TCP. A network monitoring device can then pick up on suspicious commands or output being sent over the network, for example the «systeminfo» command followed by its output from a windows host. As soon as encryption is being used by the malware (this can mean TLS, HTTPS or encryption on the application layer) this quickly becomes infeasible, even when advanced security measures like TLS- and HTTPS-interception are used.
Detecting malicious comunication by communication peer
Since the malware communicates with its handler (the beaconing), the communication peer for this communication is a weak spot for the attacker. If a defender succeeds in identifying command and control servers and detecting communication to such servers, it becomes possible to identify hosts in the defender’s network, that are most likely infected with some kind of beaconing malware. This used to be achieved relatively easily by analysing malware samples that were captured in the wild to extract IP-addresses and/or URLs as indicators of compromise (IOC) and then blacklisting all communication involving such IOCs. Of course malware operators are aware of this weakness in their operating model and have long since moved beyond addressing their C2 proxies by static URLs or IP-addresses, left alone hardcoding this information in malware.
One way to go beyond static addressing is to use domain generating algorithms that can reliably create domains from given input values (the seed values). These algorithms work deterministically in the sense that a given input or seed value will always produce the same output domain. Figure 2 illustrates this idea:

Figure 2: Illustration of domain generation algorithm (DGA)
Malware can now use such algorithms to dynamically generate URLs. If the malware operator uses the same algorithm and same seed values, the required domains can be registered ahead of time and the respective domains configured, to resolve to one or more C2 proxies. This approach makes it a lot more difficult to extract meaningful IOCs from captured malware samples and thus blacklist the corresponding malware traffic. The following Figure 3 shows an example of such a setup:
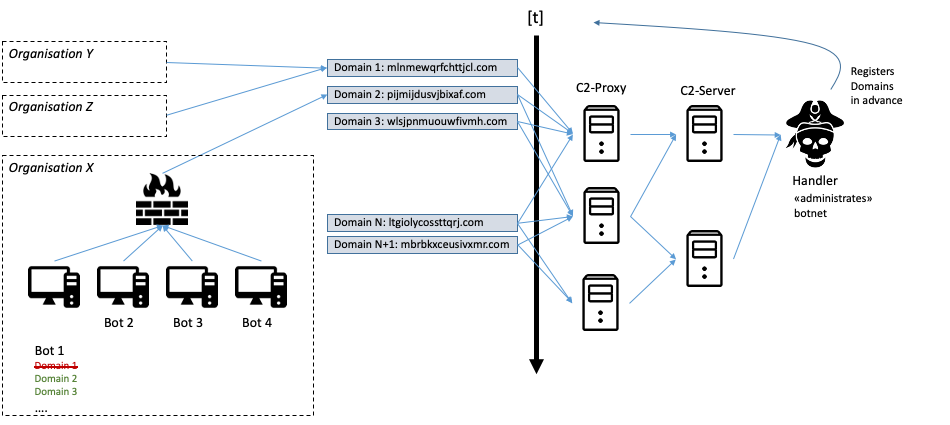
Figure 3: A typical setup involving malware comunicating with its command and control (C2) infrastructure by using domain generation algorithms
Many recently discovered threat actors have been using the abovementioned approach for their C2 communication. Examples are:
- The recently documented Flubot campaign, targeting Android devices, [5]
- The Solarwinds/Sunburst APT, [6]
A deep neural network classifier for algorithmically generated domains
A multitude of approaches to detect C2 activity as outlined above has been studied and is being used in practice. These approaches range from rather simple statistical analysis to test for the amount of randomness (or rather entropy) a given domain-name contains, to traffic inspection and analysis of content being transmitted over the network, blacklisting of IP-adresses and URLs to semantic and syntactic analysis of said URLs.
As detecting malicious communication peers can essentially be viewed as a (binary or n-ary) classification problem and deep learning models are very good at solving this kind of tasks, it makes sense to apply this kind of models in order to try and classify URLs into malicious (meaning being algorithmically generated) and benign.
In the following we’ll introduce a deep neural network model which we’ll then show to be leading to rather interesting results when applied to the .ch-zonefile.
A deep neural network is a black box model, consuming inputs (in our case domain-names) and then returning outputs (in our case a single value between 0 and 1, which we’ll interpret as a percentage or rather a certaininty between 0% and 100%). Despite a lot of research having been undertaken towards making these kinds of models more explainable and interpretable, they remain rather intransparent up until to date. The process to generate these models, however, is well understood and for the¬†(supervised learning) models we’re discussing here is as follows:
- Define the model architecture
- Train the model based on a set of training data
- Evaluate the model performance on previously unseen data
- Adjust hyperparameters and/or retrain model if necessary
Step 1.) defines the fundamental limits and kind of performance any given model can achieve. Step 2.) is basically an iterative fitting process (for which very efficient implementations, optimized for processing on GPUs are available). The aim of the training or fitting process is to improve model performance within the fundamental limits imposed by the models architecture. In step 3.) the generalizeability of the model is evaluated on previously unseen data, thus simulating a real world application of the trained model.
Satisfactory results of step 3 are an indication, that the model under consideration will likely perform well in in the future and/or in a real world setting. If the model evaluation in step 3 indicates unsatisfactory results, the model’s hyperparameters (defining the amounts and types of neurons in each layer of the neural network) have to be adjusted and/or the model has to be retrained with different / bigger datasets in a fourth step leading back to the beginning.
The following Figure 4 illustrates this process.
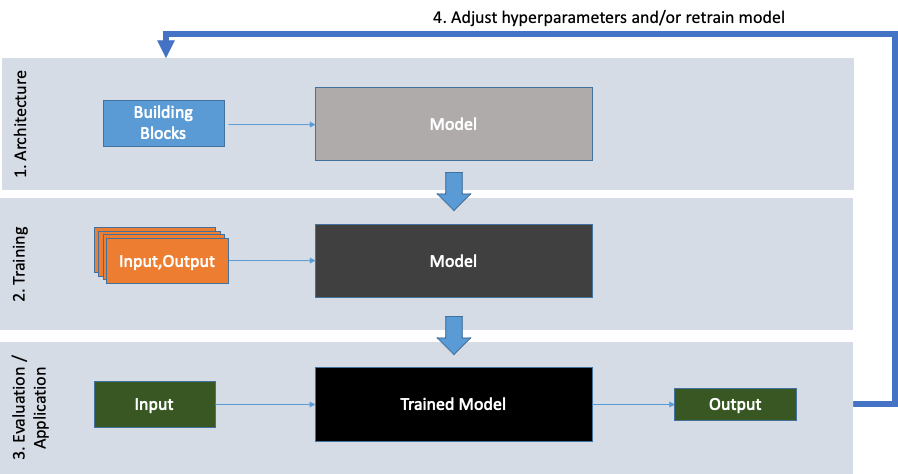
Figure 4: The development cycle for supervised machine learning models
Model architecture
Different types of deep neural networks have been studied and compared in the past, for instance in [7], which found deep neural networks to be able to classify malicious, algorithmically generated, domains with an accuracy of roughly 97-98%.
We chose to use the stacked convolutional neural network model architecture with two layers described in [7], because it was found to be comparably quick to train and evaluate while obtaining similar accuracy as other, more complicated model architectures, which require a significantly higher computational effort for training and evaluation.
Model training
The following datasets were used for initial model training and evaluation:
- Benign samples: The Cisco Popularity List Top 1M ([8])
- Malicious samples: The¬† Netlab OpenData Project’s DGA Domain list ([9])
Below are a few examples for benign and malicious samples from both lists:
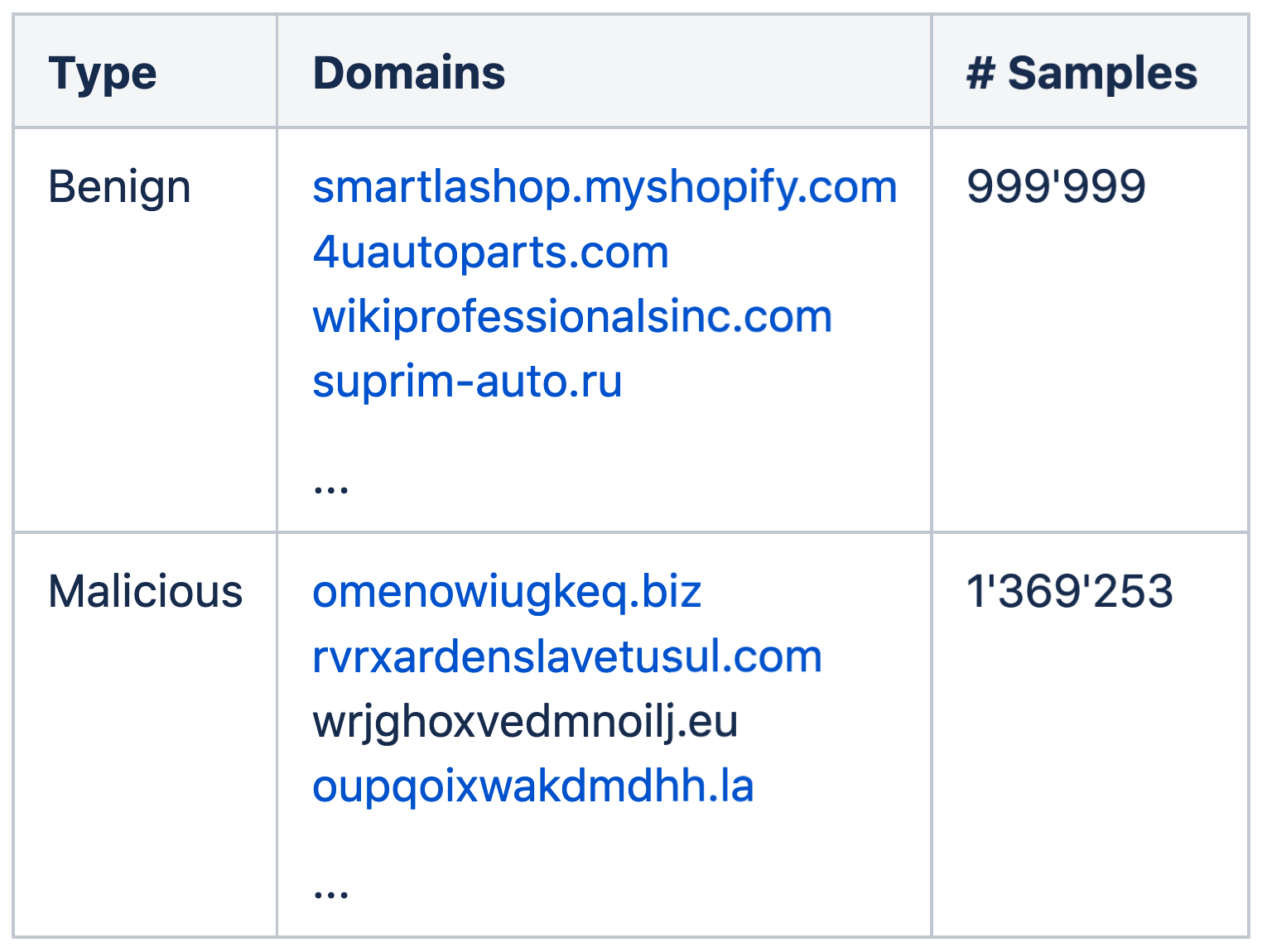
Note that most of the benign samples are not part of the Swiss .ch-zone. In fact just about slightly more than 6’000 domains from the benign list end with «.ch».
Combining and then randomly splitting (in a k-fold crossvalidation) these datasets allow us to confirm the high accuracy results found in [7]. In fact we even find an slightly higher classification accuracy of 99% in our experiments.
We thus have verified that our model implementation works and proceed by retraining the model using the full, combined 2.3 million samples on a GPU-cluster. We’ll call this the global dataset and the resulting detector the globally trained model. Once model training has finished we can move on to evaluation.
Model evaluation
To evaluate model performance, we utilize the globally trained model to classify each and every .ch-domain, found in the published zonefile ([3]). Below Figure 5 shows the model scores for all 2.3 million .ch-domains in a barchart:
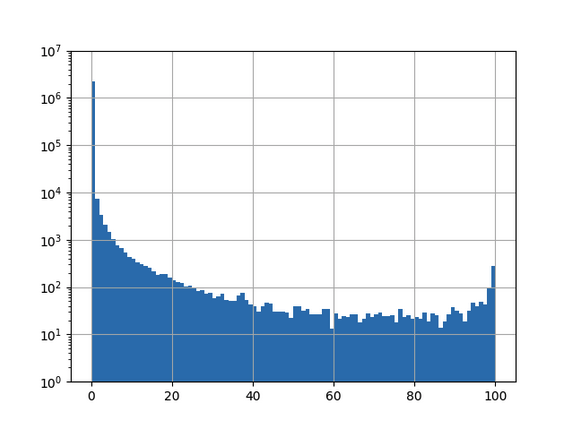
Figure 5: Result of applying the convolutional neural network trained on the global training set to the .ch-zone, 101 bins, log10-scaled y-axis.
(0, 25) 2257416
(25, 50) 1347
(50, 75) 675
(75, 100) 1024
There are some interesting false positives, especially towards the end of the last bin («feuerwehr» means fire brigade in German and the second to last line is a Swiss-german sentence) :
url proba
177355 baergbruennli.ch 100.0
221554 berufsfeuerwehr.ch 100.0
221558 berufsfeuerwehrbern.ch 100.0
227580 betriebsfeuerwehr.ch 100.0
309704 bvgauskuenfte.ch 100.0
367029 chloeoepfdiiwaeg.ch 100.0
451265 dampfvereinrhb.ch 100.0…
all of which are classified as being algorithmically generated domains (AGDs) with a 100% certainity by the globally trained model. This is not what we would expect from the very high accuracy models that we have seen in [7] and our own model verification. An additional drawback is, the sheer amount of high-certainity classifications (1’699 domains are classified as AGDs with more than 50% certainity) which renders a manual inspection of all results infeasible.
It turns out, that we can do better.
Retraining / model specialisation
As mentioned above, there are a number of options to improve model performance, such as changing the model’s hyperparameters or retraining the model with a different / bigger dataset. Exploring the model’s hyperparameter-space requires a means to automatically gauge model performance, which in our case is infeasible, because we don’t know which of the 2.3 million .ch-domains are malicious and we have no way to reliably determine this without manual inspection of the results.
We thus opt for improving the training dataset: As mentioned above, we don’t know which of the .ch-domains are malicious and which ones are benign, so retraining the model with known benign and known malicious samples from the .ch-zone is not possible. Instead we will keep the global training data and use an approximation to extend the global dataset with additional samples from the .ch-zone, that we assume to be benign. The approximation we make, is that if a given domain has at least one associated MX record, that domain is more likely to be benign than malicious, because configuring an MX record means more effort for a malicious actor.
Since we have the complete .ch-zonefile we have access to all MX records and are able to process this data efficiently. About 72% of all .ch-domains have at least one MX record, which means we can add an additional 1.6 million samples to our training-dataset. (This leads to somewhat of an imbalance in the training set, which is adressed by using class-weighting in the model training procedure). We call this datasaet the specialized dataset and the corresponding model the specialized model.
After retraining the model with all 3.9 million domains and evaluating model performance again on the whole .ch-zone we get the results in Figure 6:
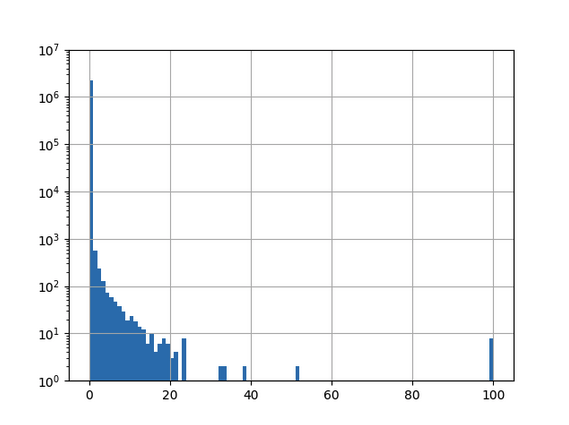
Figure 6: Result of applying the convolutional neural network trained on the specialized dataset to the .ch-zone, 101 bins, log10-scaled y-axis.
Now this distribution is strongly skewed, marking only a few domains as AGDs with high certaininty:
(0, 25) 2260430
(25, 50) 13
(50, 75) 6
(75, 100) 13
The domains classified as AGDs with a certaininty above 50% are summarized  in Figure 7 below along with the result of manually inspecting the domain and the associated IP-addresses, respectively. Manual inspection of all these domains is now feasible. We use a combined approach of looking up blacklists and manual research, very similar to what an analyst in a security operations center would do, to reach our conclusions about the domains.
Note that none of the detected domains are obvious false positives, instead all of them at least «look» somewhat suscpicious.

Figure 7: The domains classified as AGDs with a classification score above 50%.
Our approach identified 19 domains with a certainity above 50%, 9 of which are revealed to be very likely malicious and 5 of which were confirmed to be benign by manual inspection. 5 domains do not resolve to any IP-address at all and are not found on any blacklist we consulted.
Conclusion
We conclude that our method appears to work to identify a manageable amount of suspicious domains (19 domains), from a very large dataset (2.3 million domains). There still appear to be false positives in this set but at the end of the day, this process of automatically identifying highly suscpicious candidates and then manually investigating them is exactly what happens in security operation centers all over the world. Usually, however, with a much higher amount of false positives and a much higher amount of alerts.
One concern is, that 19 out of 2.3 million domains seems to be a rather low ratio of detections. This can be countered by lowering the classification threshold to lower percentages (below 50%) which in turn most likely would increase the amount of false positives. In a production setting the optimal deetction threshold would have to be investigated further.
Given the results of manually inspecting the suscpicious domains, we believe it would well be worth an analyst’s time to perform the manual analysis of domains that are detected in this way.
One can also envision additional ways to further improve the accuracy of this method by utilizing additional data and not only relying on the neural network for detection.
We intend to look further into these topics and also investigate the feasiblity of our method for other countries.
All of the above, and much more, is available in Dreamlab’s CySOC solution.
About the author and acknowledgements
Mischa Obrecht works as a cyber-security specialist in various roles for Dreamlab Technologies. He thanks Jeroen van Meeuwen (Kolabnow.com) and Sinan Sekerci (Dreamlab) for sharing their ideas, time and advice, while contributing to above research.
He also thanks Arthur Drichel from RWTH Aachen for sharing advice and an initial POC implementation of the convolutional neural network.
References
[1] https://sappan-project.eu/
[2] Analyzing the Real-World Applicability of DGA Classifiers, https://arxiv.org/abs/2006.11103
[3] https://securityblog.switch.ch/2020/11/18/dot_ch_zone_is_open_data/
[4] The CySOC SIEM-solution, https://dreamlab.net/en/solutions/cysoc/
[5] https://securityblog.switch.ch/2021/06/19/android-flubot-enters-switzerland/
[7] Bin Yu, Jie Pan, Jiaming Hu, Anderson Nascimento, and Martine De Cock. 2018.Character Level Based Detection of DGA Domain Names. InInternational JointConference on Neural Networks. IEEE, https://faculty.washington.edu/mdecock/papers/byu2018a.pdf
[8] Cisco Umbrella Project –¬† https://s3-us-west-1.amazonaws.com/umbrella-static/index.html
